مقدمه
بهبود عملکرد سازمانی از طریق استفاده از داده های بزرگ: استفاده مداوم از فناوری دیجیتال، هم توسط سازمان ها و هم توسط مصرف کنندگان، منجر به انفجار داده های جدید شده است.
با استفاده از دستگاههای قدرتمندتر، مصرفکنندگان فایلهای رسانهای را با کیفیت و در نتیجه اندازه فزاینده به اشتراک میگذارند و از پوشیدنیها، به عنوان مثال، گجت های سلامتی که همیشه روشن هستند و داده تولید میکنند، استفاده میکنند. از سوی دیگر، سازمانها بهطور مداوم زیرساختهای دیجیتالی جدیدی مانند حسگرها، تجهیزات کشاورزی هوشمند، ردیابهای موجودی را به کار میگیرند، اینها چند مورد از ابزارهایی است که این چنین داده هایی را ارائه میکنند.

طبق گزارش IBM، در سال 2020، هر فرد روی زمین 1.7 مگابایت داده در ثانیه تولید می کند. در همین راستا، فوربس پیش بینی می کند که تا سال 2025 بیش از 150 زتابایت داده بیدرنگ نیاز به تجزیه و تحلیل دارد. سازمانها از رشد دادههای بزرگ استفاده میکنند و برخی از آنها بسیار فعالانه این کار را میکنند. به عنوان مثال، مرکز تحقیقات کاربرد تجاری (BARC) بیان میکند که سازمانهایی که از مزایای دادههای بزرگ بهره میبرند، افزایش 8 درصدی درآمد را با کاهش همزمان 10 درصدی هزینهها گزارش میدهند.
این مقاله مروری بر کلان داده ارائه میکند و توصیههایی در مورد اینکه چگونه سازمانها میتوانند از دادههای بزرگ برای بهبود عملکرد خود در چندین زمینه استفاده کنند، ارائه میکند.
مطالعه پیشنهادی: مبارزه با فساد با استانداردهای ISO
داده های بزرگ (Big Data)
اولین بحث در مورد کلان داده در مقاله ای که توسط آقای داگ لین، تحلیلگر آن زمان در Forrester Research نوشته شده بود، در سال 2001 ظاهر شد. این مقاله به Big Data اشاره نکرد اما برای اولین بار سه ویژگی اصلی Big Data را مورد بحث قرار داد: حجم، سرعت و تنوع. اصطلاح Big Data تنها در سال های 2006-2007 به صورت آنلاین ظاهر شد و از آن زمان تا کنون رایج شده است.
امروز، جستجوی گوگل برای تعریف کلان داده، 1.96 میلیارد نتیجه ایجاد می کند. با این حال، این نوع تنوع ناگزیر منجر به سردرگمی قابل توجهی در مورد اینکه دادههای بزرگ چیست و سازمانها چه زمانی باید شروع به بررسی برنامهها و راهحلهای خاص مرتبط با دادههای بزرگ کنند، میشود. علاوه بر این، در نظر گرفتن تنها مقدار داده همیشه کافی نیست زیرا برخی از سازمان ها به طور معمول صدها ترابایت در ماه پردازش می کنند، در حالی که برخی دیگر با صدها گیگابایت مشکل دارند.
در عوض، یک راه این است که به داده های بزرگ به شیوه ای تجاری نگاه کنیم و اثربخشی آن را در چارچوب سازمانی در نظر بگیریم. این دیدگاه منجر به تعریفی می شود که صرفاً بر ارزش کسب و کار متمرکز است و نه بر جنبه های فنی – زمانی با Big Data سروکار داریم که نمی توانیم اطلاعات مورد نیاز را در بازه های زمانی لازم برای ارزش افزودن به فعالیت های سازمانی به دست آوریم. یا، به بیان دیگر، سازمان ها نیاز دارند که اطلاعات را قبل از رویدادهای خاص در دسترس داشته باشد. در غیر این صورت غیر قابل استفاده است.
مطالعه پیشنهادی: اخذ گواهینامه ایزو 9001
ویژگی های داده های بزرگ
سه ویژگی Big Data یا 3V که توسط آقای Laney در کارش شناسایی شده است، پایه و اساس مورد استفاده برای ایجاد طرحهای تجاری Big Data و زیرساختهای فناوری را تشکیل میدهند. در حالی که ویژگیهای جدید دائماً ظاهر میشوند و تعریف اصلی را گسترش میدهند، آنها اغلب زائد و پرمدعا به نظر میرسند که با هدف بازاریابی در ذهن ایجاد شدهاند. 3V اصلی در زیر مورد بحث قرار گرفته است.

حجم (Volume)
همانطور که از نام آن پیداست، این مشخصه به اندازه مجموعه داده هایی اشاره دارد که باید پردازش شوند. هنگام بحث در مورد حجم، ابتدا باید نحوه اندازه گیری آن را تعریف کنیم. ما به عنوان مصرف کننده و یا یک شخص حرفه ای با کیلوبایت، مگابایت، گیگابایت آشنا هستیم.
با این حال، حجم داده های بزرگ فراتر از هر یک از این مقادیر است. بنابراین تعریف در این مرحله ضروری است. فهرست زیر توضیحی درباره عباراتی که در حال حاضر برای اندازه گیری کمیت داده ها به صورت بایت بیان می شوند را ارائه می دهد:
- کیلوبایت – 1000 بایت
- مگابایت – 1000 کیلوبایت
- گیگابایت – 1000 مگابایت
- ترابایت – 1000 گیگابایت
- پتابایت – 1000 ترابایت
- اگزابایت – 1000 پتابایت
- زتابایت – 1000 اگزابایت
- یوتابایت – 1000 زتابایت
تعاریف فوق اصطلاحاً «تعاریف اعشاری» است که توسط دادگاههای حقوقی مناسبترین تعاریف در تجارت و بازرگانی است. مجلدهایی که زیر آنها خط کشیده شده است آنهایی هستند که داده های بزرگ در نظر گرفته می شوند.
علاوه بر این، ظهور COVID-19 و افزایش استفاده از فناوری دیجیتال احتمالاً این رقم را حتی بیشتر خواهد کرد.
مطالعه پیشنهادی: دستورالعمل اخذ گواهینامه تایید صلاحیت ایمنی پیمانکار
سرعت (Velocity)
سرعت دومین مشخصه کلان داده است. به سرعت ایجاد داده ها و سرعت پردازش و مصرف داده ها اشاره دارد. ظهور مدل های کسب و کار جدید، برنامه های کاربردی نوآورانه و استفاده گسترده از دستگاه های قابل حمل سرعت را به طور قابل توجهی افزایش داده است.
فدرال رزرو ایالات متحده تخمین می زند که در سال 2012 در مجموع 24.4 میلیارد تراکنش با کارت اعتباری همه منظوره انجام شد، در حالی که در سال 2018، این رقم به 40.9 میلیارد رسید که افزایش 68 درصدی را نشان می دهد. علاوه بر این، روند پرداخت های الکترونیکی به دلیل COVID-19 شتاب بیشتری خواهد گرفت، زیرا تراکنش های الکترونیکی تنها گزینه برای اکثر افراد در طول قرنطینه بود و اکنون مردم با فناوری دیجیتال بسیار راحت هستند.
با این حال، این روند حتی قبل از همهگیری زمانی که بانکها شروع به کاهش تعداد دستگاههای باجه خودکار (ATM) خود در برخی کشورها مانند استرالیا کردند، قابل مشاهده بود.
افزایش حجم پرداخت الکترونیکی تنها نمونه هایی از افزایش سرعت داده است. مثال دیگر شبکه های اجتماعی است. به عنوان مثال، مایکروسافت، شرکت مادر لینکدین، گزارش می دهد که در سه ماهه چهارم-2020، تعاملات در لینکدین 31 درصد افزایش یافته است. این تعاملات شامل متن و انواع دیگر دادهها، مانند ویدئو، صدا، گرافیک و غیره است.

مطالعه پیشنهادی: خط مشی کیفیت ISO 9001 – چگونه بیانیه خط مشی خود را بنویسید
تنوع (Variety)
وقتی به Big Data مربوط می شود، Variety به نوع منابع داده ای اشاره دارد که باید پردازش شوند. سه نوع اصلی از منابع داده وجود دارد که باید با آنها سر و کار داشته باشیم:
- ساختار یافته
- نیمه ساختار یافته
- بدون ساختار
ساختاریافته – این داده ها در سیستم های سازمانی قرار دارند و ساختار آن به خوبی تعریف شده است. به عنوان مثال می توان به حقوق و دستمزد، امور مالی یا سایر سیستم های ERP اشاره کرد.
در هر مورد، یک پایگاه داده تمام داده ها را ذخیره می کند. نمونه ای از چنین رکوردهای داده، سوابق کارکنان سیستم منابع انسانی است. در صورت لزوم حداقل شامل شناسه کارمند، نام، نام خانوادگی و سایر فیلدها خواهد بود. داده های ساختاریافته از اوایل دهه 80 وجود داشته است. این ساده ترین پردازش است و از نظر کمیت کوچکترین از سه نوع است.
نیمه ساختاریافته – این نوع داده شامل حجم زیادی از رکوردهای فردی با اندازه کوچک و ساختار رکورد ساده است. یک مثال می تواند داده های ارسال شده توسط یک کنتور برق هوشمند به یک سیستم مرکزی باشد.
هر بسته دارای فرمت یکسانی است: مهر زمانی – 10 بایت، مکان – 10 بایت، مصرف – 10 بایت + سایر اطلاعات – 80 بایت. بنابراین، اطلاعات در مورد مصرف برق 110 بایت طول می کشد. با این حال، 110 بایت گمراه کننده است زیرا حجم روزانه در شهری با 500000 خانوار با فواصل زمانی 5 ثانیه، 950 گیگابایت (110126024500000) خواهد بود. ظرف یک ماه این مجموعه داده به 11.4 ترابایت می رسد و پس از یک سال حجم آن به 137 ترابایت می رسد.
کنتورهای هوشمند برق تنها نمونه ای از داده های نیمه ساختار یافته هستند. با گسترش مداوم دستگاههای اینترنت اشیا (IoT)، دادههای نیمه ساختاریافته سریعترین رشد را در بین این سه نوع خواهند داشت.
بدون ساختار – در واقع، این داده ها ساختار یافته هستند. با این حال، در این مورد، ما با بسیاری از ساختارها و قالب های مختلف سر و کار داریم. عبارت دقیق تر چند ساختاری خواهد بود. با این حال، بدون ساختار در حال حاضر به دلایلی استفاده می شود.
نمونههایی از دادههای بدون ساختار عبارتند از پستهای رسانههای اجتماعی، مانند صدا، تصویر، گرافیک و متن. علاوه بر این، سیستمهای خارجی، دادههای منابع سازمانی، مانند فایلهای Word، ایمیلها و فایلهای PDF، در اینجا گنجانده شدهاند.
شکل 1 طیف گسترده ای از اقلام داده تولید شده در هر دقیقه در سال 2021 را نشان می دهد. برخی از نکات برجسته که به Big Data کمک می کند شامل اشتراک گذاری 240 هزار عکس در فیس بوک، تماشای 16 میلیون ویدیوی TikTok و میزبانی 856 دقیقه وبینارهای زوم است.
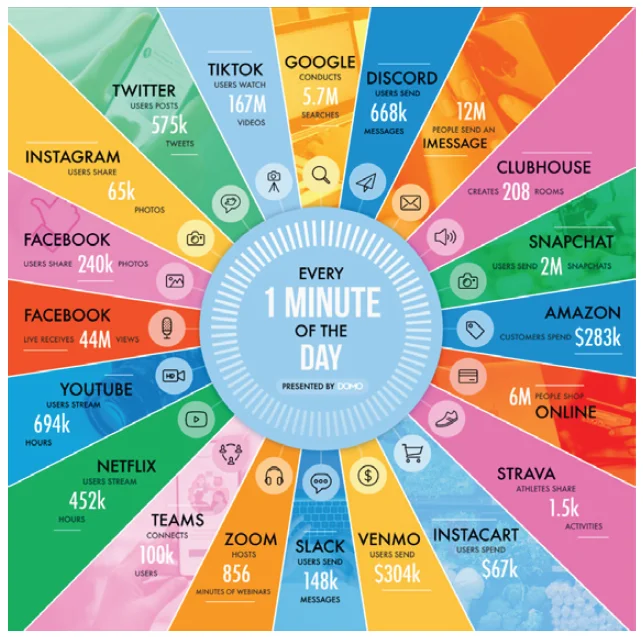
شکل 1 رشد قابل توجه مداوم در Big Data را در هر سه ویژگی – حجم، سرعت و تنوع نشان می دهد. با این حال، این اینفوگرافیک تنها بخشی از تصویر را نشان می دهد – داده های تولید شده توسط فعالیت های مصرف کنندگان فردی. حتی حجم داده های بالاتری از سازمان ها در صنایع مختلف می آید. و، مطمئناً این رشد در Big Data در طول COVID-19 و پس از آن به میزان قابل توجهی سرعت مییابد، زیرا سازمانها فناوریهای جدید را اتخاذ میکنند و زیرساختهای جدید را به کار میگیرند، در حالی که مصرفکنندگان «متصل» راههای جدیدی برای اتصال، خرید و کار کردن با اعتماد به نفس بالایی اتخاذ میکنند.
کاربردهای داده های بزرگ در بهبود عملکرد سازمانی
با توجه به تعداد زیادی از امکانات که Big Data برای سازمان ها فراهم می کند، گاهی اوقات تصمیم گیری در مورد شروع کار می تواند دلهره آور باشد.
اولین چیزی که باید در نظر گرفت این است که داده های بزرگ یک فناوری نیست بلکه یک ابتکار تجاری است. در Big Data، مانند هر پروژه دیگری، تمرکز بر فناوری به بهای از دست دادن منافع تجاری، دستوری برای شکست است.
یک رویکرد مفید در تصمیم گیری برای استفاده از کلان داده در یک سازمان، ارزیابی زنجیره ارزش سازمانی است. مایکل پورتر زنجیره ارزش را در کتاب پرفروش سال 1985 خود – مزیت رقابتی توسعه داد. یک سازمان برای ایجاد ارزش برای مشتریان خود باید این فعالیت ها را انجام دهد. به گفته پورتر، فعالیت ها مستقیماً با مزیت رقابتی و تجزیه و تحلیل آنها با عملکرد برتر مرتبط هستند.
از آنجایی که هم Big Data و هم زنجیره ارزش پورتر بر مزیت رقابتی و بهبود عملکرد تمرکز دارند، استفاده از زنجیره ارزش به عنوان یک راهنما برای Big Data یک تناسب طبیعی است. هر یک از فعالیتها کاندیدای مناسبی برای رویکرد دادههای بزرگ است، اما به تمرکز روی یک واحد در یک زمان کمک میکند. هر سازمانی بسته به عوامل متعددی مانند استراتژی، صنعت، نیروهای بازار خارجی، فرهنگ سازمانی و غیره، نقطه شروع را تعیین خواهد کرد. چندین مثال از کاربردهای کلان داده ممکن در زیر مورد بحث قرار گرفته است.
تدارکات و تقلب
انجمن بررسیکنندگان خبره تقلب (ACFE) تخمین میزند که تقلب شغلی مسئول 5 درصد از دست دادن درآمد سازمانی است. طرح های تقلب زیادی وجود دارد که رایج ترین آنها تقلب در صورتحساب است که بخشی از چرخه تدارکات است. در نتیجه، استفاده از Big Data برای شناسایی و جلوگیری از تقلب در صورتحساب به طور قابل توجهی بر سود و عملکرد تأثیر میگذارد.
یک روش برای استفاده از Big Data در برابر تقلب در صورتحساب، ترکیب ایمیلهای تامینکنندگان، تراکنشهای سیستم(های) تدارکات، مناقصه موفق و انتخاب تامینکنندگان ترجیحی است. سپس مجموعه داده به دست آمده برای شناسایی رفتار ترجیحی تامین کنندگان، با اشاره به رشوه، تجزیه و تحلیل می شود. عدم تطابق در سفارشات خرید، فاکتورها، و رسید – که منجر به اضافه صورتحساب یا تحویل کم می شود. روابط نزدیک غیرمعمول بین تامین کنندگان و کارکنان خاص که تضاد منافع را آشکار می کند.
فروش و بازاریابی
همانطور که هر بازاریاب تایید می کند، شخصی سازی کلید دستیابی به مشتریان بیشتر است. با گسترش داده های بزرگ و راه حل های مرتبط، برندها به طور فزاینده ای از داده های بزرگ برای بهبود تلاش های بازاریابی و نتایج نهایی خود استفاده می کنند.
یکی از نمونه ها مک دونالد است که از بازاریابی انبوه به سفارشی سازی انبوه حرکت می کند. بسته به زمان روز، آب و هوا، و داده های تاریخی فروش، منوهای رانندگی در رستوران های مک دونالد خاص تغییر می کند. بنابراین، نوشیدنیهای سرد در روزهای گرم برجستهتر میشوند و به جای «آیا سیبزمینی سرخ شده را با آن دوست دارید؟» ممکن است به مشتریان با صبحانه یک قهوه پیشنهاد شود.
نتفلیکس شرکت دیگری است که به طور گسترده از Big Data برای اطمینان از حفظ مشتری استفاده می کند. به عنوان مثال، نتفلیکس برنامه هایی را که کاربران در حال تماشای آن هستند و در چه ساعتی از روز، چگونه این کار را انجام می دهند ضبط می کند – تماشای یک سریال یا چند روز طول می کشد تا یک قسمت به پایان برسد، علاوه بر نوع فیلم و ژانر آن. . علاوه بر این، این شرکت در حال برنامه ریزی برای شخصی سازی نهایی، ایجاد تریلرهای جداگانه برای هر مشترک است. این نوع تلاش های کلان داده توسط نتفلیکس زیربنای نرخ حفظ مشتری خیره کننده آن – 93٪ است.
مدیریت منابع انسانی
یک رستوران زنجیره ای جهانی فست فود از Big Data برای بهبود استخدام، آموزش و مدیریت کارکنان استفاده کرد. این سازمان دادههای ساختار یافته داخلی، دادههای بدون ساختار را در قالب نظرسنجی، و دادههای نیمهساختار یافته، که از حسگرهایی که توسط کارکنان در طول شیفتهای کاری استفاده میشد، به دست میآمد، تجزیه و تحلیل کرد، حرکات و شدت تعاملات آنها را ردیابی کرد.
مجموعه دادههای کامل شامل 10000 نقطه داده، شامل دادههای مربوط به افراد، تغییرات در روزهای مختلف هفته، عملکرد مالی فروشگاهها و چهار بازار ایالات متحده بود. سپس مجموعه داده ها با استفاده از تکنیک های Big Data و هوش مصنوعی مورد تجزیه و تحلیل قرار گرفت. این تحلیل مجموعهای از بینشهای هیجانانگیز را نشان داده شده است، این نشان داد که خرد متعارف را به چالش میکشد و تأیید میکند. به عنوان مثال، تجربه قبلی و ساختار جبران خسارت چندان اهمیتی نداشت، در حالی که طول شیفت ها و مسافت رفت و آمد بر نتایج تأثیر می گذاشت.
پس از چهار ماه، این طرح داده های بزرگ مزایای قابل توجهی برای زنجیره ایجاد کرد – رضایت مشتری تا 100٪ افزایش یافت و فروش 5٪ افزایش یافت.

خلاصه
رشد Big Data قبل از سال 2020 قابل توجه بود، اما COVID-19، به دلیل محدودیت جابجایی افراد و کالاها و در نتیجه استفاده گسترده از فناوری دیجیتال، بدون شک این روند را تسریع کرد. در نتیجه، سازمان ها در حال حاضر در حال جمع آوری مقادیر قابل توجهی از داده ها هستند. کسانی که تلاش مستمری برای مهار قدرت آن می کنند، شکوفا خواهند شد. بقیه فقط در بهترین سناریو زنده خواهند ماند.
این مقاله مروری بر کلان داده و ویژگیهای آن ارائه میکند و نمونههای خاصی از اینکه چگونه دادههای بزرگ میتواند عملکرد سازمانی را بهبود بخشد، بررسی میکند. مهم است که به یاد داشته باشید که هر کلان داده باید با تمرکز بر یک نتیجه تجاری شروع شود. به سازمان هایی که تجربه کمی در این زمینه دارند توصیه می شود از زنجیره ارزش سازمانی پورتر به عنوان نقطه شروع استفاده کنند.